
图片中大意是chandler在觉得不自在时就会讲笑话。这是Chandler在和身旁的女友Monica前老男友Dr. Richard见面时很尴尬而说的话,的确搁谁都很尴尬~~
0x00 python 字符串运算符
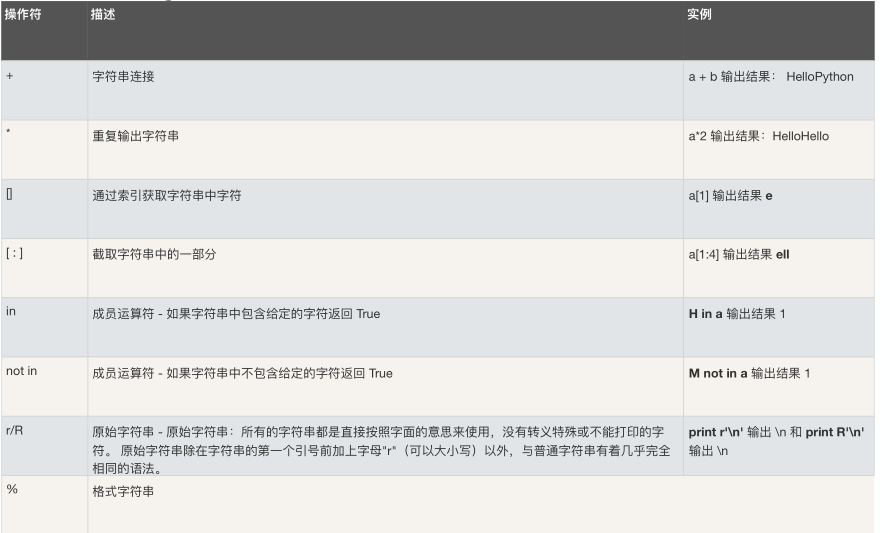
0x01 字符串格式化
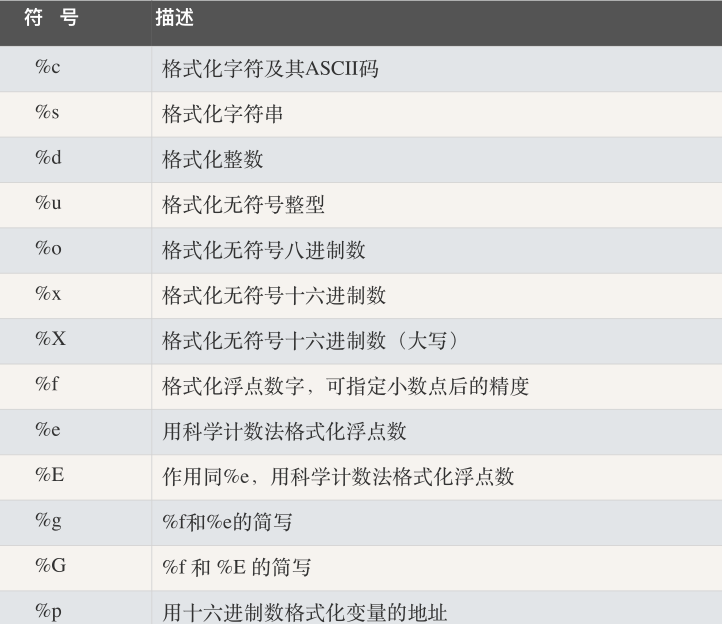
0x02 python三引号
python中三引号允许一个字符串跨多行存在,其中还能用换行符,制表符等其他特殊字符。
html代码实例
|
|
mysql代码实例
|
|
0x03 Unicode 字符串
python中在字符串引号前加一个u就是Unicode编码了,so easy
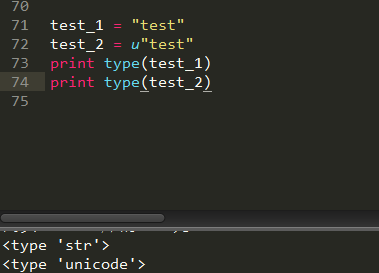
0x04 字符串操作
- 分割 list = string.split(‘,’)
- 合并 ‘,’.join(list)
- 搜索 ‘1111,22222’.find(‘,’)
- 替换 “aaaacdef”.replace(“aaaa”, “ab”);
- 长度 len(“aaaacdef”)
- 去处首尾空格 “abcdef \n”.strip()
练习代码:
sublime回显:
cmd回显:
0x05 base64编码
练习代码
sublime回显:
cmd回显: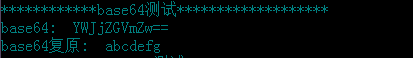
0x06 md5hash值
练习代码
sublime回显:
cmd回显:
题外话:如果你对本站文章字体有任何不适,请告知我,我会回复你,字体问题请配置浏览器,调到对眼睛舒适的大小;默认不允许转载,除非转载注明出处。
end