
一旦中了别人下的套,很难脱身了。人在江湖身不由己。
你猜中了开头 却猜不到这结局,谁又何尝不是呢。
幸好是梦一场
0x00 简介
本次爬补天的厂商,目前共115页。
能实现和需要加入的功能有
- [x] 每次使用都可爬厂商列表
- [x] 把爬去的列表写入文件里
- [ ] 补全厂商列表中有缺失URL或者厂商名字
- [ ] 多线程爬取
待办事宜TODO表暂时不支持,X位置为已有功能。
没有多线程的情况下爬了几分钟,等过阵子研究了多线程,就让代码效率高点~
先附上代码 可给我点亮小星星哦
效果图为写入到一个txt文档内。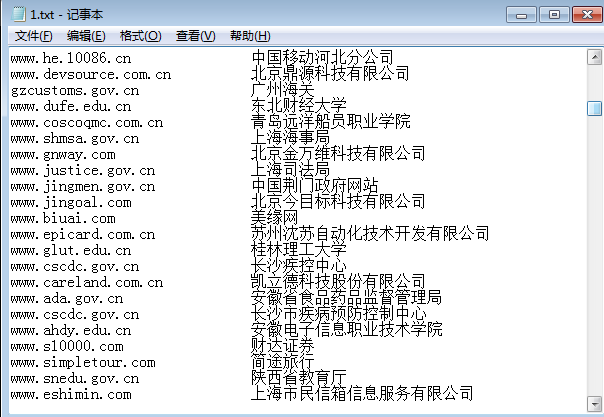
0x01 代码用到的知识
从用到的每一个非自定义函数介绍
utf-8
如果要在python2的py文件里面写中文,则必须要添加一行声明文件编码的注释,否则python2会默认使用ASCII编码。
具体英文介绍可参考 Python 的 官网详细说明
1.必须将编码注释放在第一行或者第二行
2.可选格式有
|
|
|
|
import requests
试图使用get方法从url中获取源代码可以使用urllib2 或者Requests。
然后我在知乎搜的时候搜到了scrapy,嗯说的这个框架很好用,省很多代码,我看新手就练练手不用了。
快速上手
|
|
获取某个网页 r = requests.get("https://www.baidu.com")
可以这样发送一个HTTP POST请求:r = requests.post("https://www.baidu.com/post")
为url 传参
其他详细内容参考 Python Requests快速入门
能实现的效果
- 国际化域名和 URLs
- Keep-Alive & 连接池
- 持久的 Cookie 会话
- 类浏览器式的 SSL 加密认证
- 基本/摘要式的身份认证
- 优雅的键/值 Cookies
- 自动解压
- Unicode 编码的响应体
- 多段文件上传
- 连接超时
- 适用于 Python 2.6—3.4
- 线程安全
spilt & find
由于暂时没有用到正则,所以使用查找和分割
split
Python split()通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串
语法
str.split(str=””, num=string.count(str)).
- str – 分隔符,默认为空格。
- num – 分割次数。
在练习代码中我以">末页分割,">末页之前为0,之后为1.
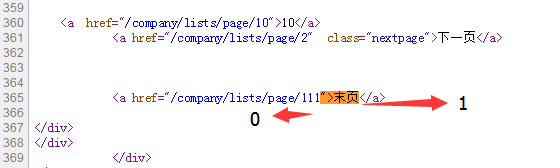
再使用rfind倒序查’/‘,再+1偏移就得到了总页数111,之前写的时候是115…难道又减少几页厂商?

rfind
Python rfind() 返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
语法
str.rfind(str, beg=0 end=len(string))
- str – 查找的字符串
- beg – 开始查找的位置,默认为0
- end – 结束查找位置,默认为字符串的长度。
文件操作
在代码中我使用了
分别open一个文件以追加的模式,再write换行写入url和厂商名,然后关闭文件,节省资源。
具体的可参照 Python文件操作
0x02 小谈
1.在使用split 分割时候一定要结合源代码分析,不能只在sublime里面一个一个改测试。
2.ljust(30)是左占30字节,但是有的网址大于30字节,在txt里面显示很长。得适当改长度。
3.PEP 8 的规范标注改的多了,感觉英文能力上升了不少~
题外话:如果你对本站文章字体有任何不适,请告知我,我会回复你,字体问题请配置浏览器,调到对眼睛舒适的大小;默认不允许转载,除非转载注明出处。
end